وقعت شركة ميتا (Meta) هذا الأسبوع في مأزق، بعد أن استخدمت إصداراً تجريبياً غير مُعلن من نموذج الذكاء الاصطناعي الخاص بها Llama 4 Maverick لتحقيق نتيجة مرتفعة على منصة التقييم الجماعي LM Arena. هذا التصرف دفع القائمين على المنصة إلى الاعتذار، وتعديل سياساتهم، ومن ثم إعادة تقييم النموذج باستخدام نسخته الرسمية غير المعدّلة.
والنتيجة؟ الأداء لم يكن على المستوى المتوقع.
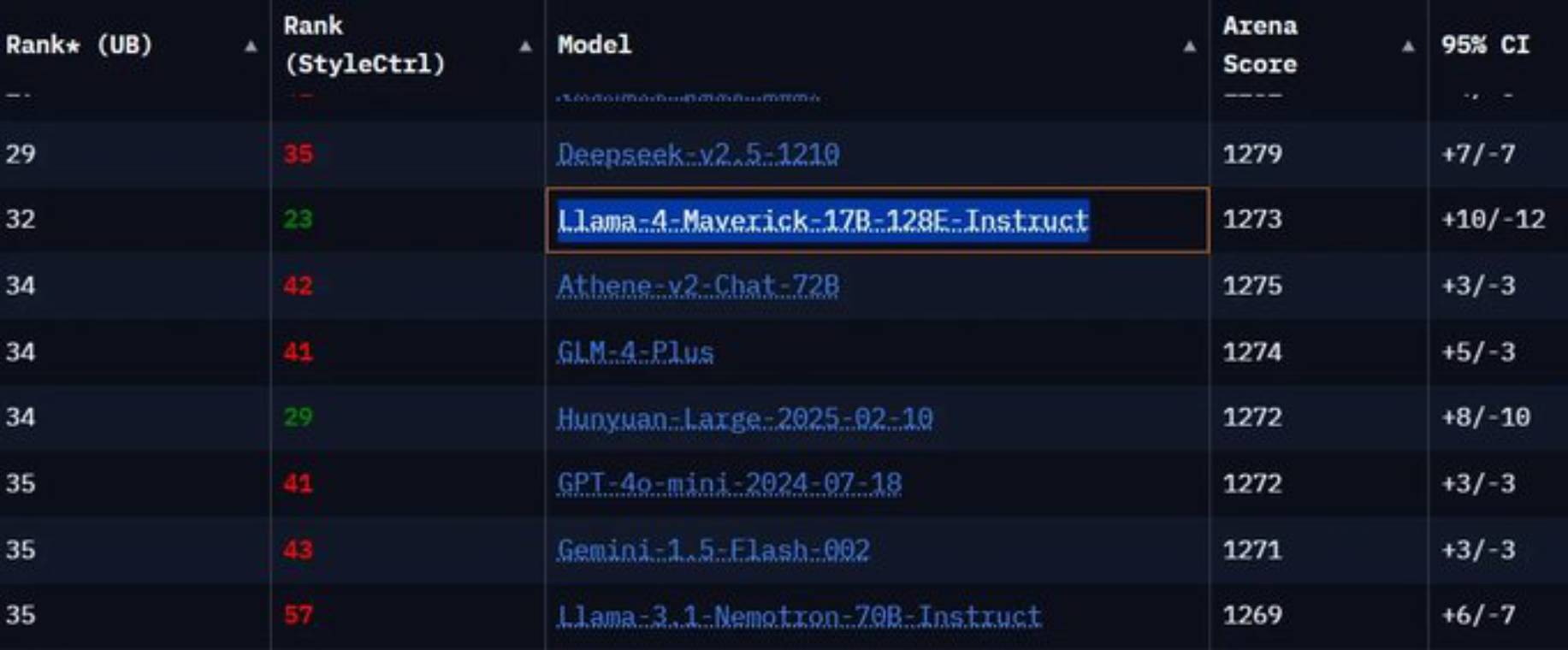
النموذج غير المعدّل، الذي يحمل الاسم "Llama-4-Maverick-17B-128E-Instruct"، جاء ترتيبه متأخراً خلف نماذج مثل GPT-4o من OpenAI، وClaude 3.5 Sonnet من Anthropic، وGemini 1.5 Pro من Google، وهي نماذج صدرت قبل أشهر.
كما أشار أحد المستخدمين على منصة "إكس" (تويتر سابقاً) إلى أن النسخة الرسمية من Llama 4 تمت إضافتها لاحقاً إلى منصة LM Arena، بعد اكتشاف "التحايل"، لكنها جاءت في المرتبة 32، وهو ما يفسر سبب عدم ملاحظتها من قبل كثيرين.
أوضحت ميتا أن النسخة التجريبية المسماة "Llama-4-Maverick-03-26-Experimental" كانت "محسّنة من أجل المحادثة"، وفقاً لجدول بياني نشرته الشركة يوم السبت الماضي. ويبدو أن هذه التحسينات منحت النموذج أفضلية في منصة LM Arena، التي تعتمد على تقييم بشري لمخرجات النماذج واختيار الأفضل منها.
ومع أن LM Arena لم تُعرف يوماً كمقياس موثوق لأداء النماذج، فإن تعديل النموذج ليتلاءم مع آلية تقييم المنصة يُعد أمراً مضللاً، كما أنه يُصعّب على المطورين التنبؤ بكيفية أداء النموذج في سيناريوهات استخدام مختلفة.
في بيان لموقع TechCrunch، قال متحدث باسم ميتا إن الشركة تقوم بتجربة "جميع أنواع النماذج المعدّلة".
وأضاف:
"النسخة التجريبية 'Llama-4-Maverick-03-26-Experimental' هي إصدار محسّن للمحادثة اختبرناه، وقد أدّى جيداً على منصة LM Arena. الآن، أطلقنا نسختنا مفتوحة المصدر وسنرى كيف سيقوم المطوّرون بتخصيص Llama 4 حسب احتياجاتهم. نحن متحمسون لما سيتم بناؤه، ونتطلع إلى تلقي ملاحظاتهم المستمرة."